Chapter 12 Comparing several means (one-way ANOVA)
This chapter introduces one of the most widely used statistical tools known as “the analysis of variance”, which is usually referred to as ANOVA. Sir Ronald Fisher developed the basic technique in the early 20th century, and it is to him that we owe the rather unfortunate terminology.
The term ANOVA is a little misleading in two respects. Firstly, although the technique’s name refers to variances, ANOVA is concerned with investigating differences in means. Secondly, several different things out there are all referred to as ANOVAs, some of which have only a very tenuous connection to one another. Later in the book, we’ll encounter various ANOVA methods that apply in quite different situations. Still, for this chapter, we’ll only consider the simplest form of ANOVA, in which we have several different groups of observations. We’re interested in finding out whether those groups differ in terms of some outcome variable of interest. This is the question that is addressed by a one-way ANOVA.
After introducing the data, we’ll describe the mechanics of the one-way ANOVA, how to calculate effect sizes and post hoc tests. We’ll also talk about how to check for normality and homoscedasticity.
Now let’s run a clinical trial!
12.1 The data
Suppose you’ve become involved in a clinical trial in which you are testing a new antidepressant drug called Joyzepam. In order to construct a fair test of the drug’s effectiveness, the study involves three different medications to be administered. One is a placebo, and the other is an existing antidepressant / anti-anxiety drug called Anxifree. A collection of 18 participants with moderate to severe depression are recruited for your initial testing. Because the drugs are sometimes administered in conjunction with psychological therapy, your study includes 9 people undergoing cognitive behavioural therapy (CBT) and 9 who are not. Participants are randomly assigned (doubly blinded, of course) a treatment, such that there are 3 CBT people and 3 no-therapy people assigned to each of the 3 drugs. A psychologist assesses the mood of each person after a 3 month run with each drug: and the overall improvement in each person’s mood is assessed on a scale ranging from to .
With that as the study design, let’s load our data file: clinicaltrial.csv. We have three variables: drug, therapy and mood_gain. Next, let’s print the data frame to get a sense of what the data actually look like.
For the purposes of this chapter, what we’re really interested in is the effect of drug on mood_gain. The first thing to do is use the Compare groups function. (But don’t jump ahead by adding both drug and therapy to the Group(s) box. That’s going to be our factorial ANOVA in Chapter 13.)
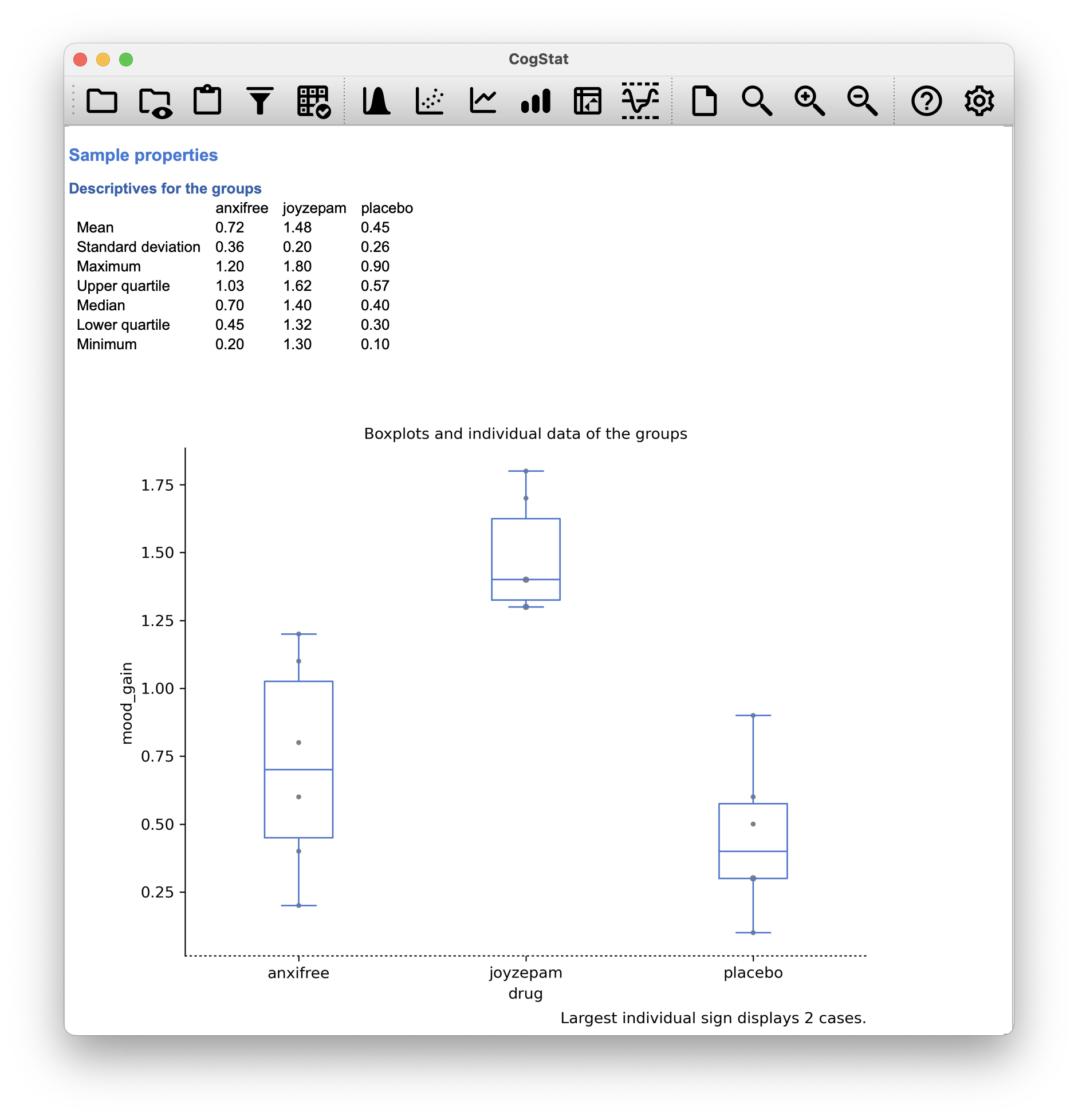
Figure 12.1: Mood gain by drug
The results are shown in the boxplot in Figure 12.1, which plots the average mood gain for all three conditions; error bars show upper and lower quartile. As the plot makes clear, there is a larger improvement in mood for participants in the Joyzepam group than for either the Anxifree group or the placebo group. The Anxifree group shows a larger mood gain than the control (i.e. placebo) group, but the difference isn’t as large.
The question that we want to answer is: are these difference “real”, or are they just due to chance?
12.2 How ANOVA works
In order to answer the question posed by our clinical trial data, we’re going to run a one-way ANOVA. As usual, we’re going to start by showing you how to do it the hard way to make sure you really understand how ANOVA works, but with CogStat, you’ll never ever have do it this way.
The experimental design strongly suggests that we’re interested in comparing the average mood change for the three different drugs. In that sense, we’re talking about an analysis similar to the -test (Chapter 11), but involving more than two groups. If we let denote the population mean for the mood change induced by the placebo, and let and denote the corresponding means for our two drugs, Anxifree and Joyzepam, then the (somewhat pessimistic) null hypothesis that we want to test is that all three population means are identical: that is, neither of the two drugs is any more effective than a placebo.
Sidenote. This assumption of equal variances is Fisher’s ANOVA. When we are explicitly not assuming equal variances, we should be using Welch’s ANOVA, but that’s covered in this book or in CogStat actually.
Back to our Fisher’s one-way ANOVA. Mathematically, we write this null hypothesis like this:
As a consequence, our alternative hypothesis is that at least one of the three different treatments is different from the others. It’s a little trickier to write this mathematically, because there are quite a few different ways in which the null hypothesis can be false. So for now we’ll just write the alternative hypothesis like this:
This null hypothesis is a lot trickier to test than any of the ones we’ve seen previously. How shall we do it? A sensible guess would be to “do an ANOVA”, since that’s the title of the chapter, but it’s not particularly clear why an “analysis of variances” will help us learn anything useful about the means. In fact, this is one of the greatest conceptual difficulties that people have when first encountering ANOVA. To see how this works, let us talk about variances first.
12.2.1 From variance…
We’ll use to refer to the total number of groups. For our data set, there are three drugs, so there are groups. Next, we’ll use to refer to the total sample size: there are a total of people in our data set. Similarly, let’s use to denote the number of people in the -th group. In our fake clinical trial, the sample size is for all three groups.56 Finally, we’ll use to denote the outcome variable (mood change). Specifically, we’ll use to refer to the mood change experienced by the -th member of the -th group. Similarly, we’ll use to be the average mood change, taken across all 18 people in the experiment, and to refer to the average mood change experienced by the 6 people in group .
Excellent. Now that we’ve got our notation sorted out, we can start writing down formulas. To start with, let’s recall the formula for the variance that we used in Chapter 5.2, way back in those kinder days when we were just doing descriptive statistics. The sample variance of is defined as follows: This formula looks pretty much identical to the formula for the variance in Chapter 5.2. The only difference is that we are now summing over groups (i.e. values for ) and over the people within the groups (i.e. values for ).
Let’s consider a simple table to see how this formula works on our clinical trial data set. The table below shows the person, the drug they were given, and their mood change.
| 1 | placebo | 1 | 0.5 |
| 2 | placebo | 2 | 0.3 |
| 3 | placebo | 3 | 0.1 |
| 4 | anxifree | 1 | 0.6 |
| 5 | anxifree | 2 | 0.4 |
| 6 | … | … | … |
Our average mood change is the mean of all the mood changes in the data set (which you can see if you run Explore variable for mood_gain), which is . The variance of the mood changes is the sum of the squared differences between each mood change and the average mood change, divided by the total number of observations. So our formula filled in would look like this:
Fortunately, we don’t have to do these manually.57
12.2.2 … to total sum of squares
Okay, now that we’ve got a good grasp on how the population variance is calculated, let’s define something called the total sum of squares, which is denoted . This is very simple: instead of averaging the squared deviations, which is what we do when calculating the variance, we just add them up. So the formula for the total sum of squares is almost identical to the formula for the variance: When we talk about analysing variances in the context of ANOVA, what we’re really doing is working with the total sums of squares rather than the actual variance. One very nice thing about the total sum of squares is that we can break it up into two different kinds of variation. Firstly, we can talk about the within-group sum of squares, in which we look to see how different each individual person is from their own group mean: where is a group mean.
In our example, would be the average mood change experienced by those people given the -th drug. So, instead of comparing individuals to the average of all people in the experiment, we’re only comparing them to those people in the same group. As a consequence, you’d expect the value of to be smaller than the total sum of squares, because it’s completely ignoring any group differences – that is, the fact that the drugs (if they work) will have different effects on people’s moods.
Next, we can define a third notion of variation which captures only the differences between groups. We do this by looking at the differences between the group means and grand mean . In order to quantify the extent of this variation, what we do is calculate the between-group sum of squares:
It’s not too difficult to show that the total variation among people in the experiment is actually the sum of the differences between the groups and the variation inside the groups . That is:
Yay.

Figure 12.2: Graphical illustration of “between-groups” variation

Figure 12.3: Graphical illustration of “within groups” variation
Okay, so what have we found out?
We’ve discovered that the total variability associated with the outcome variable () can be mathematically carved up into the sum of “the variation due to the differences in the sample means for the different groups” () plus “all the rest of the variation” ().
Let’s apply the formulas to our clinical trial example, and see what we get. We won’t bother with the calculations in details, because the formula is given, and CogStat will not bore you with these either.
How does that help me find out whether the groups have different population means? If the null hypothesis is true, then you’d expect all the sample means to be pretty similar to each other, right? And that would imply that you’d expect to be really small, or at least you’d expect it to be a lot smaller than the “the variation associated with everything else”, .
So, let’s do a hypothesis test to validate.
12.2.3 From sums of squares to the -test
As we saw in the last section, the qualitative idea behind ANOVA is to compare the two sums of squares values and to each other: if the between-group variation is large relative to the within-group variation , then we have reason to suspect that the population means for the different groups aren’t identical to each other.
Our test statistic is called an -ratio. It’s defined as the ratio of the between-group variation to the within-group variation.
In order to convert our SS values into an -ratio, the first thing we need to calculate is the degrees of freedom associated with the SS and SS values. As usual, the degrees of freedom corresponds to the number of unique “data points” that contribute to a particular calculation, minus the number of “constraints” that they need to satisfy.
For the within-groups variability, what we’re calculating is the variation of the individual observations ( data points) around the group means ( constraints). In contrast, for the between-groups variability, we’re interested in the variation of the group means ( data points) around the grand mean (1 constraint). Therefore, the degrees of freedom here are:
What we do next is convert our summed squares value into a “mean squares” value, which we do by dividing by the degrees of freedom:
Finally, we calculate the -ratio by dividing the between-groups MS by the within-groups MS:
At a very general level, the intuition behind the statistic is straightforward: bigger values of means that the between-groups variation is large, relative to the within-groups variation. As a consequence, the larger the value of , the more evidence we have against the null hypothesis. (To read more on how large does have to be to reject the null hypothesis, see the next chapter.)
In order to complete our hypothesis test, we need to know the sampling distribution for if the null hypothesis is true. Not surprisingly, the sampling distribution for the statistic under the null hypothesis is an distribution. As seen in Chapter 7, the distribution has two parameters, corresponding to the two degrees of freedom involved: the first one df is the between-groups degrees of freedom df, and the second one df is the within-groups degrees of freedom df.
A summary of all the key quantities involved in a one-way ANOVA, including the formulas showing how they are calculated, is shown in Table 12.1.
| Between groups | Within groups | |
|---|---|---|
| Degrees of freedom | ||
| Sum of squares | SS | SS |
| Mean squares | ||
| statistic | - | |
| value | [complicated] | - |
Now let’s calculate these for our clinical trial example, again, behind the scenes. Let’s start with the degrees of freedom.
Now that that’s done, we can calculate the mean squares values.
Finally, we can calculate the -ratio.
12.2.4 Further reading: the meaning of (advanced)
At a fundamental level, ANOVA is a competition between two different statistical models, and . If you recall, our null hypothesis was that all of the group means are identical to one another. If so, then a natural way to think about the outcome variable is to describe individual scores in terms of a single population mean , plus the deviation from that population mean. This deviation is usually denoted and is traditionally called the error or residual associated with that observation. Be careful though: just like we saw with the word “significant”, the word “error” has a technical meaning in statistics that isn’t quite the same as its everyday English definition. The word “residual” is a better term than the word “error”. In statistics, both words mean “leftover variability”: that is, “stuff” that the model can’t explain.
In any case, here’s what the null hypothesis looks like when we write it as a statistical model: where we make the assumption that the residual values are normally distributed, with mean 0 and a standard deviation that is the same for all groups. To use the notation that we introduced in Chapter 7 we would write this assumption like this:
What about the alternative hypothesis, ? The only difference between the null hypothesis and the alternative hypothesis is that we allow each group to have a different population mean. So, if we let denote the population mean for the -th group in our experiment, then the statistical model corresponding to is: where, once again, we assume that the error terms are normally distributed with mean 0 and standard deviation . That is, the alternative hypothesis also assumes that
Okay, now that we’ve described the statistical models underpinning and in more detail, it’s now pretty straightforward to say what the mean square values are measuring and what this means for the interpretation of .
It turns out that the within-groups mean square, MS, can be viewed as an estimator (in the technical sense: Chapter 8) of the error variance . The between-groups mean square MS is also an estimator; but what it estimates is the error variance plus a quantity that depends on the true differences among the group means. If we call this quantity , then we can see that the -statistic is basically where the true value if the null hypothesis is true, and if the alternative hypothesis is true (e.g. ch. 10 Hays, 1994). Therefore, at a bare minimum the value must be larger than 1 to have any chance of rejecting the null hypothesis. Note that this doesn’t mean that it’s impossible to get an -value less than 1. What it means is that, if the null hypothesis is true the sampling distribution of the ratio has a mean of 1,58 and so we need to see -values larger than 1 in order to safely reject the null.
To be a bit more precise about the sampling distribution, notice that if the null hypothesis is true, both MS and MS are estimators of the variance of the residuals . If those residuals are normally distributed, then you might suspect that the estimate of the variance of is chi-square distributed. Because (as discussed in Chapter 7.4.4) that’s what a chi-square distribution is: it’s what you get when you square a bunch of normally-distributed things and add them up. And since the distribution is (again, by definition) what you get when you take the ratio between two things that are distributed, we have our sampling distribution.
12.3 Interpreting our results in CogStat
You already know the answers because we calculated it step by step, but you have a more in-depth understanding of how it all ties together. CogStat will do all of this for you, but it’s good to know what’s going on behind the scenes. Let’s see how CogStat displays our data.
So what we had to do, was simply run the Compare groups function with mood_gain by drug.
Figure 12.4: CogStat dialogue for Compare groups function with our clinical trial data set with variables mood_gain grouped by drug.
Figure 12.5: CogStat result set displaying descriptives and boxplots as a result of Compare groups function with our clinical trial data set with variables mood_gain grouped by drug.
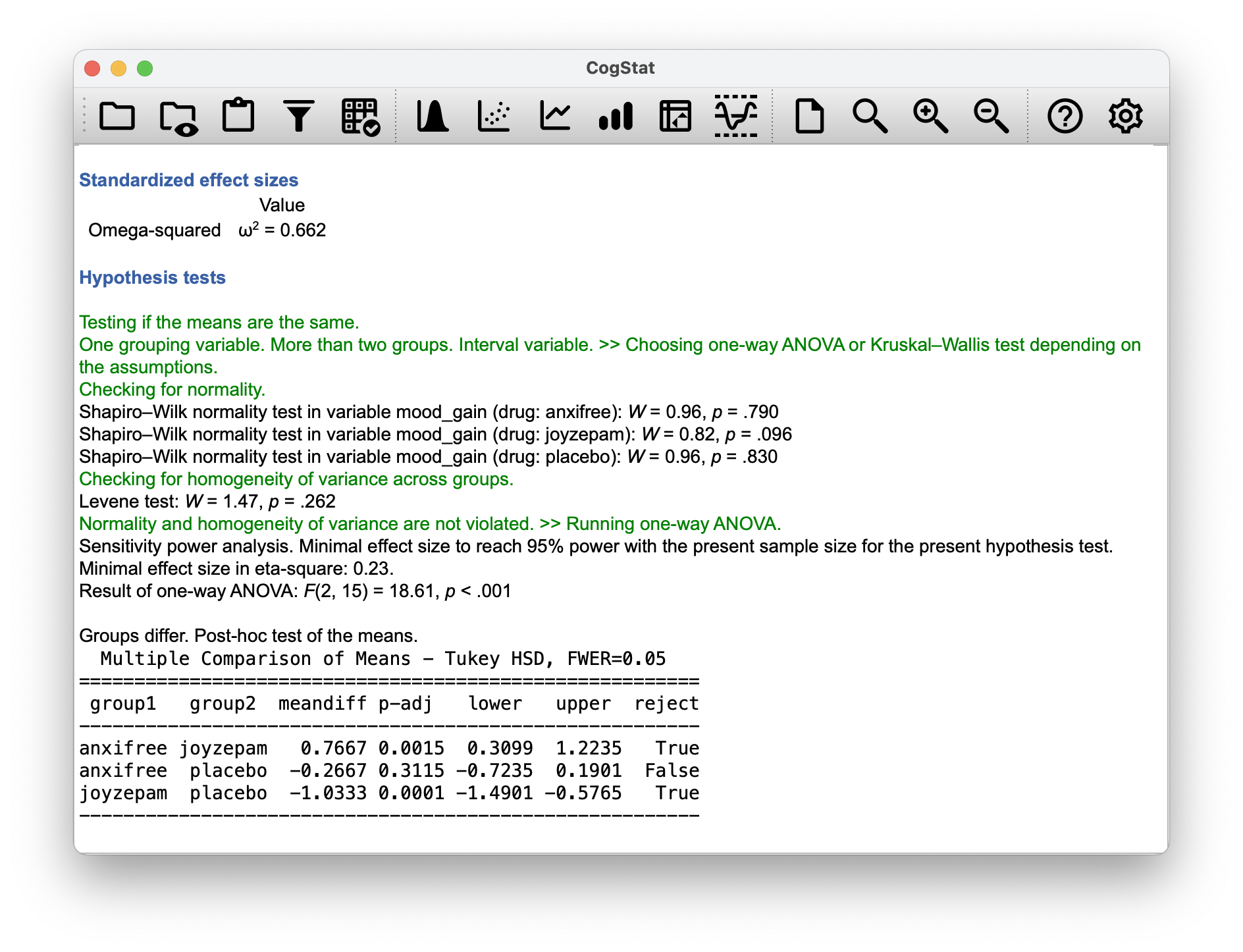
Figure 12.6: CogStat result set with hypothesis test results, effect size and post hoc results after running Compare groups function with our clinical trial data set with variables mood_gain grouped by drug.
We’ve seen this before. Let us explore the hypothesis test results.
Hypothesis tests
Testing if the means are the same.
One grouping variable. More than two groups. Interval variable. >> Choosing one-way ANOVA or Kruskal-Wallis test depending on the assumptions.
Checking for normality.
Shapiro-Wilk normality test in variable mood_gain (drug: anxifree): W = 0.96, p = .790
Shapiro-Wilk normality test in variable mood_gain (drug: joyzepam): W = 0.82, p = .096
Shapiro-Wilk normality test in variable mood_gain (drug: placebo): W = 0.96, p = .830
Checking for homogeneity of variance across groups.
Levene test: W = 1.47, p = .262
Normality and homogeneity of variance are not violated. >> Running one-way ANOVA.
Sensitivity power analysis. Minimal effect size to reach 95% power with the present sample size for the present hypothesis test. Minimal effect size in eta-square: 0.23.
Result of one-way ANOVA: F(2, 15) = 18.61, p < .001
For now, let’s stop here. We’ll come back to the post hoc tests later. For now, let’s just focus on the hypothesis test results. We can see that the Shapiro-Wilk normality test was run on each of the groups. Testing the normality assumption is relatively straightforward. We covered the theory behind it in Chapter 11.7. The Levene test was run to check for homogeneity of variance across groups. The one-way ANOVA was run, and the result was that the -value was 18.61, and the -value was less than 0.001.
At this point, we’re basically done. (If you ran the test with us, you’ve seen something about post hoc tests. We will discuss them later.) Having completed our calculations, it’s traditional to organise all these numbers into an ANOVA table like the one in Table 12.2. For our clinical trial data, the ANOVA table would look like this:
| df | Sum of squares | Mean squares | -statistic | -value | |
|---|---|---|---|---|---|
| between groups | 2 | 3.4533 | 1.7267 | 18.61 | < .001 |
| within groups | 15 | 1.3917 | 0.0928 | – | – |
CogStat doesn’t produce this table for you or give the sums of squares or mean squares. But actually, you don’t need it to understand what the statistic tells you. There’s almost never a good reason to include the whole table in your write-up, but you might see it in other statistical software.
A pretty standard way of reporting this result would be to write something like this:
One-way ANOVA showed a significant effect of drug on mood gain (F(2,15) = 18.61, p < .001).
Sigh. So much work for one short sentence (if you do it manually).
12.4 Effect size
There’s a few different ways you could measure the effect size in an ANOVA.
12.4.1 Eta-squared
One of the most commonly used measures are (eta-squared). The definition of is actually really simple:
That’s all it is. So when looking at the ANOVA table above, we see that and . Thus we get an value of
The interpretation of is equally straightforward: it refers to the proportion of the variability in the outcome variable (mood_gain) that can be explained in terms of the predictor (drug). A value of means that there is no relationship at all between the two, whereas a value of means that the relationship is perfect. Better yet, the value is very closely related to a squared correlation (i.e. ). So, if you’re trying to figure out whether a particular value of is big or small, it’s sometimes useful to remember that
can be interpreted as if it referred to the magnitude of a Pearson correlation. So in our drugs example, the value of 0.71 corresponds to an value of . If we think about this as being equivalent to a correlation of about .84, we’d conclude that the relationship between drug and mood.gain is strong.
12.4.2 Omega-squared
There’s an interesting blog post59 by Daniel Lakens suggesting that eta-squared itself is perhaps not the best measure of effect size in real world data analysis, but rather omega-squared () is. CogStat also opts for omega-squared as the default measure of effect size in one-way ANOVA.
The formula for is a little more complicated than for , because it takes into account the degrees of freedom of the two sums of squares. The formula is specific for between-subjects, fixed effects designs. The formula is:
where is the degrees of freedom for the between-subjects factor, and is the mean square for the within-subjects factor, is the total sum of squares, and is the between-subjects sum of squares. Filled in, we get:
CogStat will give you this exact omega-squared value when running the one-way ANOVA inside the Compare groups function (see result set in Figure 12.6).
will take on values between and , where 0 indicates there is no effect whatsoever. It is wise to quote the effect size when writing up our results in APA-styled psychology research60. For example, we could write:
One-way ANOVA showed a significant effect of drug on mood gain (F(2,15) = 18.61, p < .001, = 0.662).
12.5 Post hoc tests
Any time you run an ANOVA with more than two groups, and you end up with a significant effect, the first thing you’ll probably want to ask is which groups are actually different from one another.
In our drugs example, our null hypothesis was that all three drugs (placebo, Anxifree and Joyzepam) have the exact same effect on mood. But if you think about it, the null hypothesis is actually claiming three different things all at once here. Specifically, it claims that:
- Your competitor’s drug (Anxifree) is no better than a placebo (i.e., )
- Your drug (Joyzepam) is no better than a placebo (i.e., )
- Anxifree and Joyzepam are equally effective (i.e., )
If any one of those three claims is false, then the null hypothesis is also false. So, now that we’ve rejected our null hypothesis, we’re thinking that at least one of those things isn’t true. But which ones? All three of these propositions are of interest: you certainly want to know if your new drug Joyzepam is better than a placebo, and it would be nice to know how well it stacks up against an existing commercial alternative (i.e., Anxifree). It would even be useful to check the performance of Anxifree against the placebo: even if Anxifree has already been extensively tested against placebos by other researchers, it can still be very useful to check that your study is producing similar results to earlier work.
When we characterise the null hypothesis in terms of these three distinct propositions, it becomes clear that there are eight possible “states of the world” that we need to distinguish between:
| possibility: | is ? | is ? | is ? | which hypothesis? |
|---|---|---|---|---|
| 1 | null | |||
| 2 | alternative | |||
| 3 | alternative | |||
| 4 | alternative | |||
| 5 | alternative | |||
| 6 | alternative | |||
| 7 | alternative | |||
| 8 | alternative |
By rejecting the null hypothesis, we’ve decided that we don’t believe that #1 is the true state of the world. The next question to ask is, which of the other seven possibilities do we think is right? When faced with this situation, it usually helps to look at the data. For instance, if we look at the plots in Figure 12.1, it’s tempting to conclude that Joyzepam is better than the placebo and better than Anxifree, but there’s no real difference between Anxifree and the placebo. However, if we want to get a clearer answer about this, it might help to run some tests.
There are actually quite a lot of different methods for performing multiple comparisons in the statistics literature (Hsu, 1996), and it would be beyond the scope of an introductory text like this one to discuss all of them in any detail. That being said, there’s one tool of importance, namely Tukey’s “Honestly Significant Difference”, or Tukey’s HSD for short. While there is the possibility to run “pairwise” -tests manually in other statistical software, CogStat opts for Tukey’s HSD test as a robust tool for running post hoc tests.
The basic idea of Tukey’s HSD is to examine all relevant pairwise comparisons between groups, and it’s only really appropriate to use Tukey’s HSD if it is pairwise differences that you’re interested in. If, for instance, you actually would find yourself interested to know if Group A is significantly different from the mean of Group B and Group C, then you need to use a different tool (e.g., Scheffe’s method, which is more conservative, and beyond the scope this book).
Tukey’s HSD constructs simultaneous confidence intervals for all the comparisons. What we mean by 95% “simultaneous” confidence interval is that there is a 95% probability that all of these confidence intervals contain the relevant true value. Moreover, we can use these confidence intervals to calculate an adjusted value for any specific comparison.
Let’s look at the post hoc test result coming from CogStat, as seen in Figure 12.6.
| group1 | group2 | meandiff | p-adj | lower | upper | reject |
|---|---|---|---|---|---|---|
| anxifree | joyzepam | 0.7667 | 0.0015 | 0.3099 | 1.2235 | True |
| anxifree | placebo | -0.2667 | 0.3115 | -0.7235 | 0.1901 | False |
| joyzepam | placebo | -1.0333 | 0.0001 | -1.4901 | -0.5765 | True |
The first column shows one of the groups in our comparison, namely the drug. The second column shows which other group we are comparing against in pairs. The third column is our statistic (the mean difference), and the fourth column is the adjusted value. The fifth and sixth columns show the lower and upper bounds of the 95% confidence interval for the mean difference. The final column shows whether or not we reject the null hypothesis that the mean difference is zero.
The easiest way to interpret the results is to look at what pairs have rejected the null hypothesis (of not having a significant difference).
In our case, we see in the first result line that Joyzepam is significantly better than Anxifree, because the mean difference is positive (meaning an improvement from Anxifree to Joyzepam), our -value is less than 0.05, and the confidence interval does not include zero. The last column indicates we rejected the null hypothesis.
We also see in the third line that Joyzepam is significantly better than the placebo because the mean difference is negative from Joyzepam to placebo. The -value is less than 0.05, and the confidence interval does not include zero, and the last column indicates we rejected the null hypothesis.
In the second line, from Anxifree to the placebo, we see a negative mean difference, meaning that while Anxifree looks like it’s performing better than the placebo (as we’ve seen in the boxplot as well), the confidence interval does include zero, and the -value is greater than 0.05, so we fail to reject the null hypothesis.
What we would write up next to our ANOVA result is the following:
Post hoc tests indicated that Joyzepam produced a significantly larger mood change than both Anxifree (p = .002) and the placebo (p < .001). We found no evidence that Anxifree performed better than the placebo (p = .31).
12.6 Checking the homogeneity of variance assumption
There’s more than one way to skin a cat, as the saying goes, and more than one way to test the homogeneity of variance assumption, too. The most commonly used test for this is the Levene test (Levene, 1960), which CogStat uses.61
Levene’s test is shockingly simple. Suppose we have our outcome variable . All we do is define a new variable, say, , corresponding to the absolute deviation from the group mean:
The value of is a measure of how the -th observation in the -th group deviates from its group mean. And our null hypothesis is that all groups have the same variance; that is, the same overall deviations from the group means. So the null hypothesis in a Levene’s test is that the population means of are identical for all groups. Isn’t that what ANOVA is? Yes. All that the Levene’s test does is run an ANOVA on the new variable 62.
If we look at the output from Cogstat (Figure 12.6), we see that the test is non-significant . So it looks like the homogeneity of variance assumption is fine.
12.7 Testing for non-normal data with Kruskal-Wallis test
CogStat automatically checked for normality, and we covered the Shapiro-Wilk test in Chapter 11.7. However, let’s talk about removing the normality assumption. In the context of a one-way ANOVA, the easiest solution is probably to switch to a non-parametric test (i.e. one that doesn’t rely on any particular assumption about the kind of distribution involved). We’ve seen non-parametric tests before, in Chapter 11: when you only have two groups, the Wilcoxon test provides the non-parametric alternative that you need. When you’ve got three or more groups, though, you can use the Kruskal-Wallis rank sum test (Kruskal & Wallis, 1952).
The Kruskal-Wallis test is a non-parametric alternative to the one-way ANOVA, and it is surprisingly similar to it in some ways. It is a rank-based test, meaning that it doesn’t actually look at the values of the data, but rather at the order of the data.
In ANOVA, we started with , the value of the outcome variable for the th person in the th group. For the Kruskal-Wallis test, what we’ll do is rank order all of these values and conduct our analysis on the ranked data. So let’s let refer to the ranking given to the th member of the th group. Now, let’s calculate , the average rank given to observations in the th group: and let’s also calculate , the grand mean rank:
Now that we’ve done this, we can calculate the squared deviations from the grand mean rank . When we do this for the individual scores – i.e., if we calculate – what we have is a “non-parametric” measure of how far the -th observation deviates from the grand mean rank. When we calculate the squared deviation of the group means from the grand means – i.e., if we calculate – then what we have is a non-parametric measure of how much the group deviates from the grand mean rank. With this in mind, let’s follow the same logic that we did with ANOVA, and define our ranked sums of squares measures in much the same way that we did earlier. First, we have our “total ranked sums of squares”: and we can define the “between-groups ranked sums of squares” like this:
So, if the null hypothesis is true and there are no true group differences at all, you’d expect the between group rank sums to be very small, much smaller than the total rank sums . Qualitatively this is very much the same as what we found when we went about constructing the ANOVA -statistic; but for technical reasons the Kruskal-Wallis test statistic, usually denoted (but let’s not conflate with “hypothesis”!). In CogStat, you’ll see . The official formula is: and, if the null hypothesis is true, then the sampling distribution of is approximately chi-square with degrees of freedom (where is the number of groups). The larger the value of , the less consistent the data are with null hypothesis, so this is a one-sided test: we reject our null hypothesis when is sufficiently large.
At a conceptual level, this is the right way to think about how the test works. However, from a purely mathematical perspective, it’s needlessly complicated. The equation for can be rewritten as
The story is true when there are no ties in the raw data. That is, if there are no two observations that have exactly the same value. If there are ties, then we have to introduce a correction factor to these calculations. At this point, even the most diligent reader might have stopped caring (or at least formed the opinion that the tie-correction factor is something that doesn’t require their immediate attention). So let us omit the tedious details about why it’s done this way. We can look at a frequency table for the raw data (under Explore variable), and let be the number of observations that have the -th unique value.
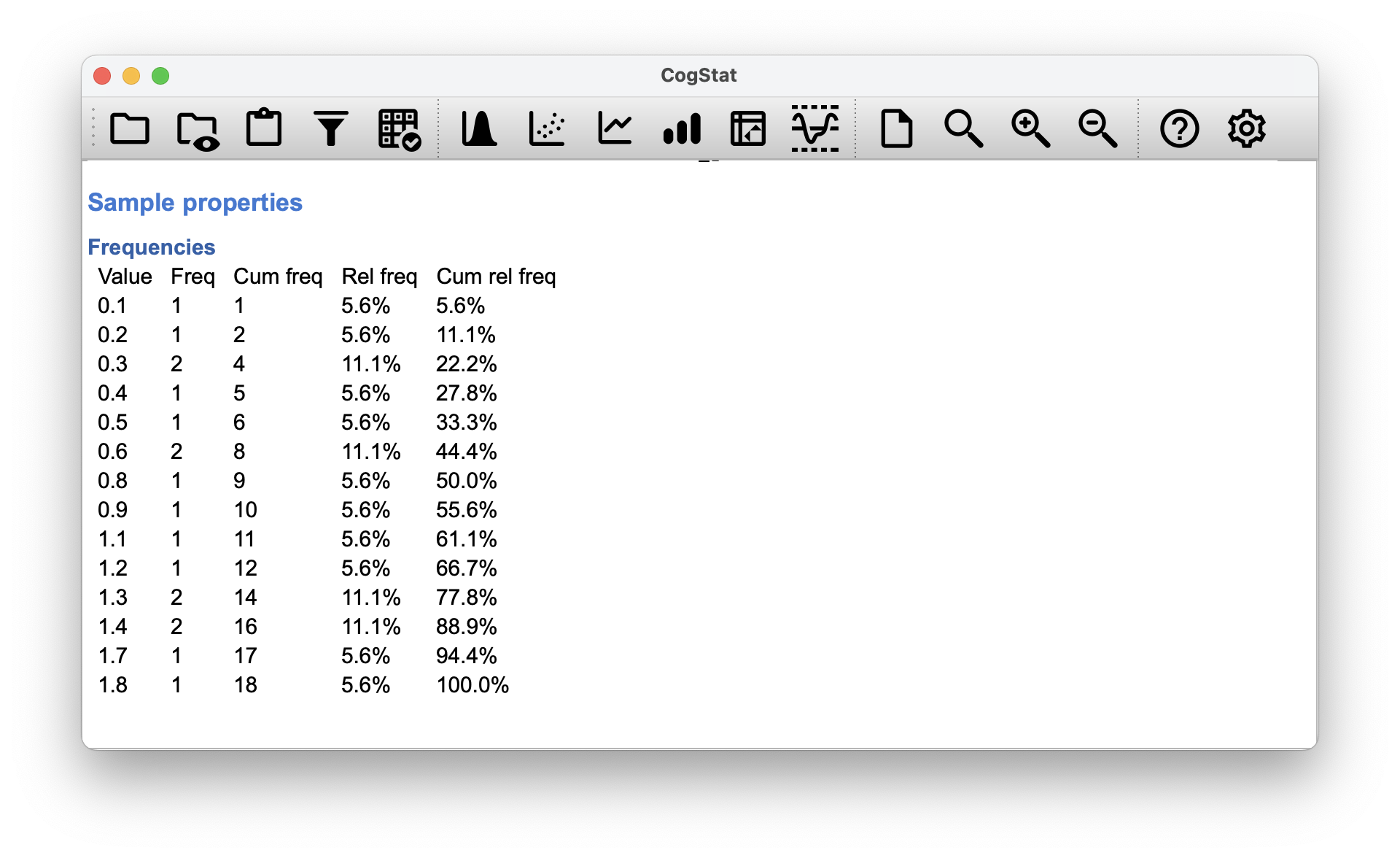
Figure 12.7: Frequency table for the raw data (mood_gain).
Looking at this table, notice that the value of (and , , ) has a frequency of 2. This is telling us that two people’s mood increased by 0.3 (and 0.6…). More to the point, note that we can say , where 3 is the index of the value (i.e. row number 3). Yay. So, now that we know this, the tie correction factor (TCF) is: The tie-corrected value of the Kruskal-Wallis statistic obtained by dividing the value of by this quantity.
If the data was non-normal, CogStat would automatically calculate the non-parametric test. However, it’s normal, so you’ll just have to trust us that the results are
However, it’s good to take a look at how CogStat would display the results for non-normal data, particularly because the post hoc test results are different.
So, here’s some tweaking of our clinical trial data with the placebo results not meeting the normality assumption: clinical_nonnormal.csv (the placebo group’s data is more “flat” when plotted). Let’s load it in CogStat and explore the Compare groups result set.
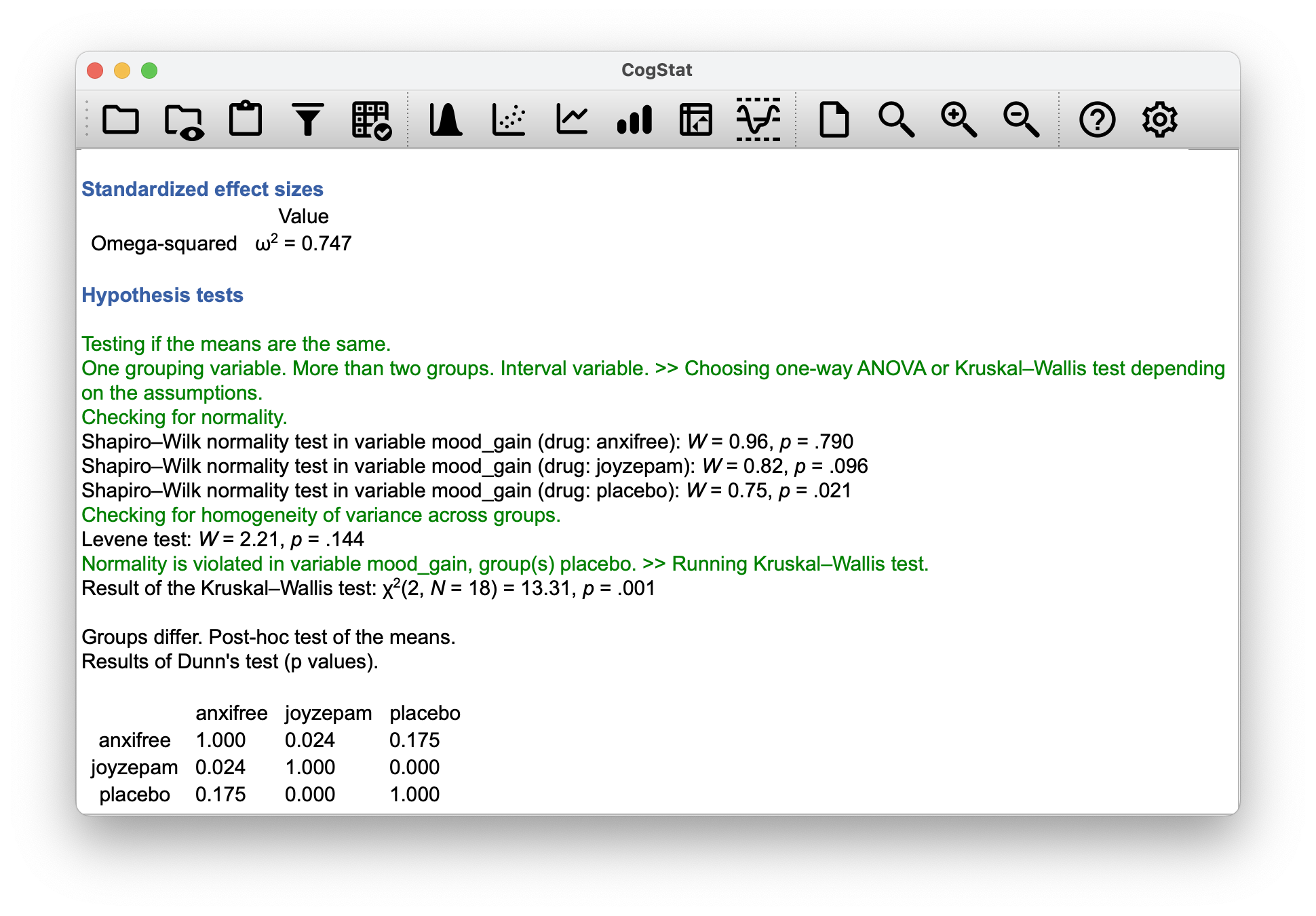
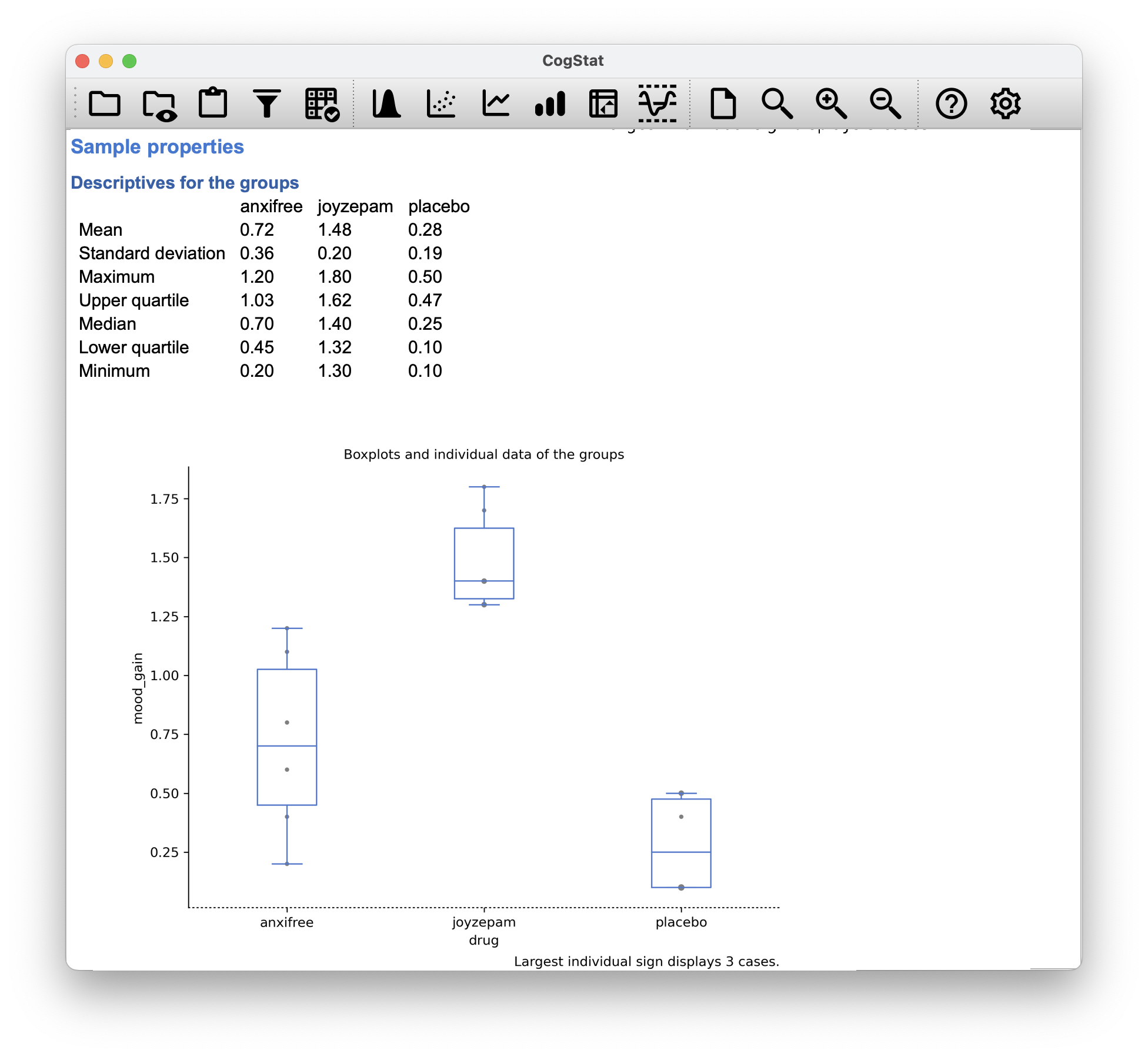
Figure 12.8: CogStat results for the non-normal data.
The boxplot shows we have a similar setup to our original data, but we see that the placebo group’s mood_gain is not normally distributed (because the Shapiro-Wilk test is significant with , and also the mood gain is now flattened on purpose for the sake of the exercise), so CogStat automatically calculates the non-parametric test. The results are:
Result of the Kruskal-Wallis test:
This is pretty straightforward: the test statistic proves that the null hypothesis is false. Now let’s look at the post hoc results:
We see that CogStat ran the Dunn’s Multiple Comparison Test for the non-normal data post hoc analysis. This is a pairwise comparison with 5% significance level. From the table, you cannot read a specific statistic to show what are the differences between the groups and what is their direction, but you see a -value of significance.
So what you can do, is list all the pairs where is significant, and then you can look at the boxplot to see the direction of the difference (or more scientifically, the descriptive statistics results where you have the means for each group).
For example, we see two pairs, where the is significant ():
- The first pair is Joyzepam and Anxifree, where (regardless if you read it by column or row). This means that the difference between the two groups is significant, but we don’t know the direction of the difference. We can look at the boxplot to see that the Joyzepam group has a higher mean than the Anxifree group, and we can quantify it by looking at the means: for Anxifree, and for Joyzepam. So Joyzepam is more effective than Anxifree, and the result is significant.
- The second (and final) pair is Joyzepam and the placebo, where , or more formally, . This means that the difference between the two groups is significant, and we can see that Joyzepam () has a higher mean than the placebo (). So Joyzepam is more effective than the placebo, and the result is significant.
Our effect size is calculated with omega-squared as before, which, for this altered data set is: .
Our write-up would be something along the lines of:
The Kruskal-Wallis test showed a significant effect of drug on mood gain (H(2, N=18) = 13.31, p = .001, = .747$). Post hoc tests indicated that Joyzepam produced a significantly larger mood change than both Anxifree (p = .024) and the placebo (p < .001). We found no evidence that Anxifree performed better than the placebo (p = .175).
And we’re done.
12.8 On the relationship between ANOVA and the Student -test
It’s something that a lot of people find kind of surprising but it’s worth knowing about: an ANOVA with two groups is identical to the Student -test. It’s not just that they are similar, but they are actually equivalent in every meaningful way. Suppose that, instead of running an ANOVA on our mood_gain ~ drug model, let’s instead do it using therapy as the predictor. If we run this in Compare group, CogStat automatically selects the independent sample -test, as we’ve seen in Chapter 11. Here’s the result when running the therapy model:
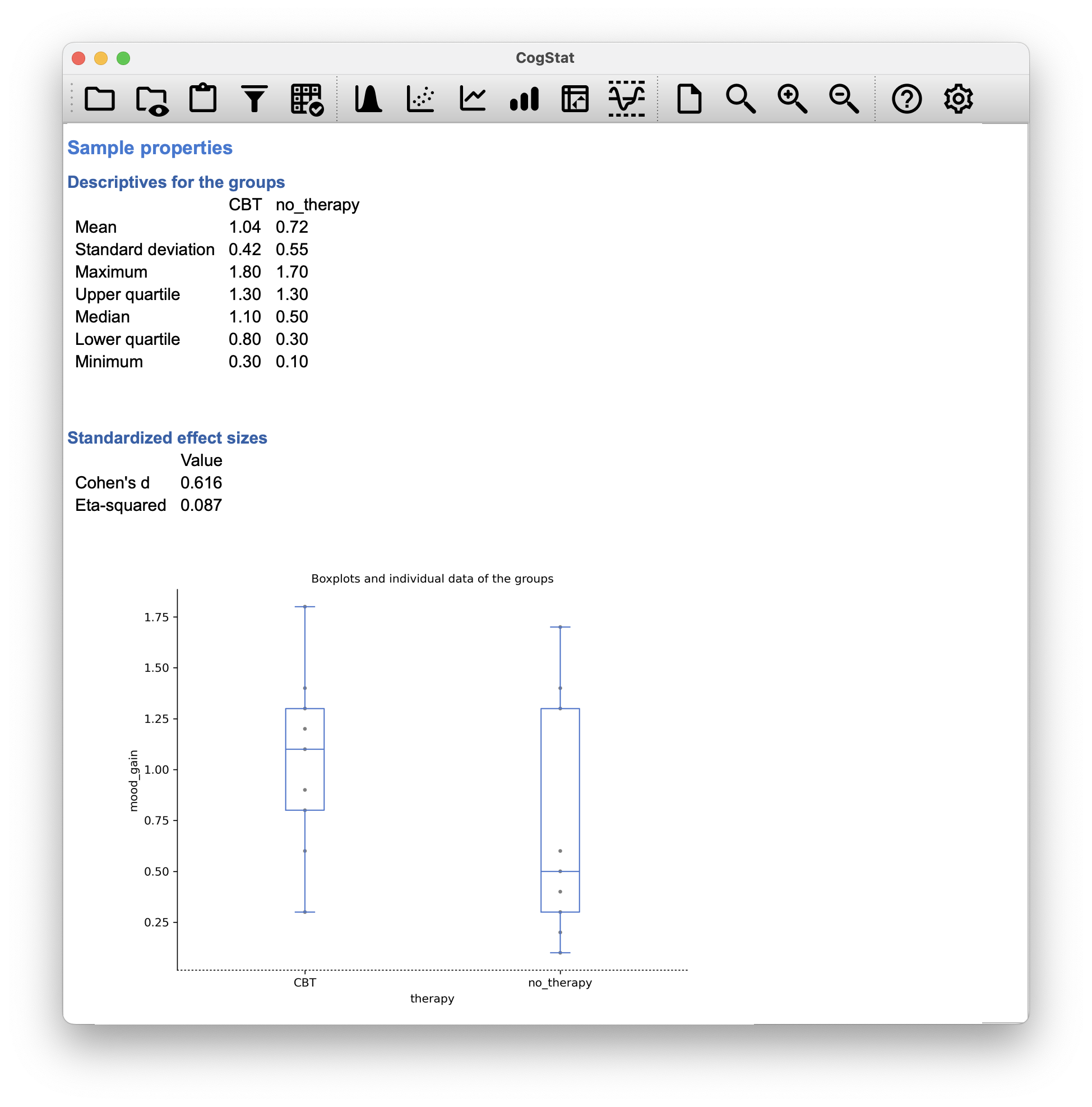
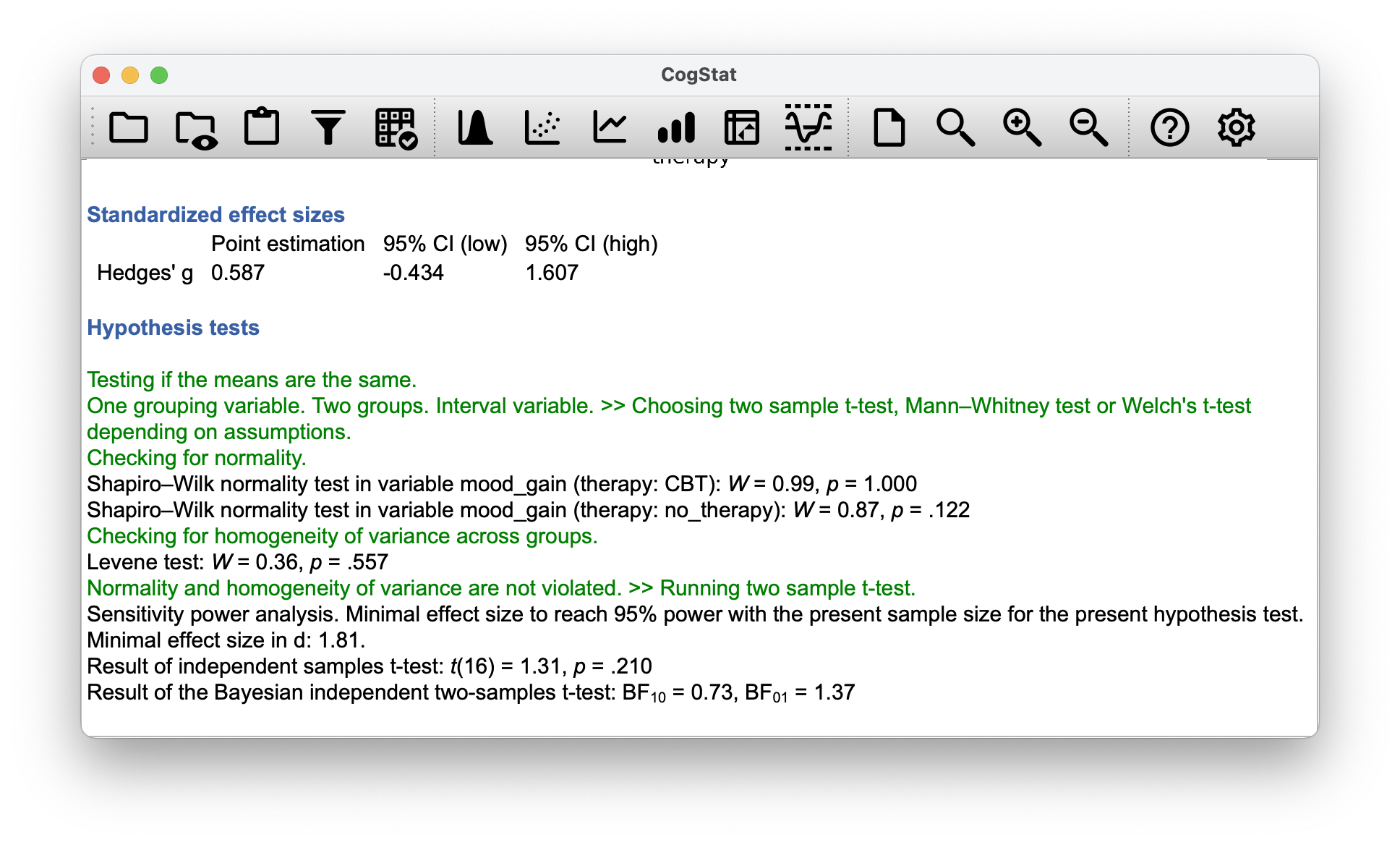
Figure 12.9: CogStat results for the therapy model.
Having run a -test, we get (or more precisely, – you’ll see why this is important). The -value is . Should we run a one-way ANOVA -statistic in another software, we’d see , and the -value, which is – not surprisingly – .
But hang on, what is the story with the and statistics? Actually, there is a fairly straightforward relationship here. If we square the -statistic:
we get the -statistic from before:
Such fun!
12.9 Summary
Like any statistical test, analysis of variance relies on some assumptions about the data.
- Normality. The residuals are assumed to be normally distributed. As we saw in Chapter 11.7, we can assess this by looking at QQ plots or running a Shapiro-Wilk test. If normality fails, we can run a Kruskal-Wallis test instead (see Chapter 12.7).
- Homogeneity of variance. Notice that we’ve only got the one value for the population standard deviation (i.e. ), rather than allowing each group to have its own value (i.e. ). This is referred to as the homogeneity of variance or homoscedasticity assumption. ANOVA assumes that the population standard deviation is the same for all groups. See Chapter 12.6. If the homogeneity of variance assumption fails, CogStat runs the Kruskal-Wallis test instead (see Chapter 12.7), similarly to when the normality assumption is violated.
- Independence. The independence assumption is a little trickier. What it basically means is that, knowing one residual tells you nothing about any other residual. All of the values are assumed to have been generated without any “regard for” or “relationship to” any of the other ones. There’s not an obvious or simple way to test for this, but there are some situations that are clear violations of this: for instance, if you have a repeated measures design, where each participant in your study appears in more than one condition, then independence doesn’t hold. When that happens, you need to use repeated measures ANOVA (accessible in
Compare repeated measures variable).
Some parts of this chapter was influenced by Sahai & Ageel (2000), which is an excellent book for more advanced readers who are interested in understanding the mathematics behind ANOVA.
References
When all groups have the same number of observations, the experimental design is said to be “balanced”. Balance isn’t such a big deal for one-way ANOVA but becomes more important when you start doing more complicated ANOVAs.↩︎
You went into Excel and did it manually, and got the same answer, great! No, you used the
VAR.Pfunction and got the same answer. Great! Wait, you used theVAR.Sand got ? Something’s not right. You went to jamovi or JASP or SPSS (because you’re fancy) and got . What happened? There is a difference between population variance and estimated variance. The population variance is the variance of the population based on the fact you know all members of the population – which is the case in our example, as we need the population variance of our trial, not the population to which the trial results will extend to. The estimated variance is always going to be a little bit bigger than the population variance, because it’s an estimate, and uses a slightly different formula. Namely, it multiplies by , not .↩︎Or, more accurately, .↩︎
http://daniellakens.blogspot.com.au/2015/06/why-you-should-use-omega-squared.html↩︎
https://apastyle.apa.org/instructional-aids/numbers-statistics-guide.pdf↩︎
There’s the closely related Brown-Forsythe test (Brown & Forsythe, 1974) as well, which is what CogStat uses.↩︎
What about the Brown-Forsythe test? Does that do anything particularly different? Nope. The only change from the Levene’s test is that it constructs the transformed variable in a slightly different way, using deviations from the group medians rather than deviations from the group means.↩︎